Rails診察カルテ: アプリで何か変わったことをしてませんか?(翻訳)
🔗 要約
レガシーなRailsアプリケーションは、こちらの予想を覆すこともあるので、「こう振る舞うのが普通」という思い込みは禁物です。
アプリケーションを安定させるための第一歩は、オブザーバービリティ(observability: 可観測性)を改善すること、すなわち、システムに手を加える前に、システムの振る舞いをきちんと理解することです。
また、現実のデータを利用してボトルネックを特定し、重要な設定項目を最適化し、何か問題が発生したら即座にデプロイを取り消せるようにしておくことです。システムのコンカレンシー設定のチューニングのような微細な調整であっても、システムの信頼性に多大な影響を及ぼす可能性があります。
🔗 助けを求める声
ある日、Railsアプリケーションが不安定で困っているので助けて欲しいという依頼が弊社の受信ボックスに届きました。障害や速度低下が頻々と発生しているにもかかわらず、根本原因を突き止められないのだそうです。依頼主はサードパーティの監視サービスを用いて監視とアラートを実装していたので、これによって問題が発覚しました。
🔗 患者の症状
問題のアプリケーションはB2BのEコマースプラットフォームで、主に以下の3つのコンポーネントで構成されていました。
- 一般公開用Webサイト(Railsアプリケーション)
- レガシーなERP(Enterprise Resource Planning)システム: (中身はブラックボックス)
- 上記2つの通信を担当するミドルウェア(別のRailsアプリケーション)
ここにはオブザーバービリティもログ集約も実装されていませんでした。
アプリケーションのデプロイ先はAWS EC2インスタンス上でした。
デプロイのプロセスは、AnsibleとカスタムビルドのRailsアプリケーションを用いて自動化され、デプロイ用のプレイブックを実行するようになっていました。
ただしこのデプロイ用アプリケーションにはロールバック機能がないため、デプロイが失敗した場合は変更を取り消してCIテストの完了を待ってから、再度デプロイを実行しなければなりませんでした。
2つのRailsアプリは同一インスタンス上で実行されていて、両者は分離されていませんでした。どちらのアプリケーションがサーバーリソースをより多く消費しているかについては、htopなどのリアルタイムシステム監視ツールを使わない限り検出不可能でした。
アプリケーションサーバーは2つあり、どちらも同じアプリケーションのセットを実行していました。さらに、ロードバランサー(Haproxy)も2つあり、うち1つが一般公開用Webサイトを向き、他方がミドルウェアを向いていました。
停止から回復するにはインスタンスを手動で再起動しなければならず、非常に悪い状況でした。
🔗 準備段階
まずは、RailsアプリケーションにNewRelicによるinstrumentation(計測)を追加しました。また、サーバーにNewRelicのインフラエージェントもインストールしておきたいと考えました。インフラストラクチャはAnsibleで管理されていたため、既存のAnsibleロールとプレイブックを拡張してインフラエージェントをインストールしました。
🔗 調査 -- 第1ラウンド
最初の大きな発見は、一般公開用Webサイトが無限ループに陥っていたことでした。これはNewRelicのプロファイリング機能で特定しました。障害発生中にプロファイリングセッションを実行して、慎重に分析しました。
この無限ループの原因は、外部ERPシステム側のAPI変更がRailsアプリケーションのコードに反映されていなかったことが原因でした。私たちがこのことを指摘すると、顧客のチームはすぐさま修正できました。
残念ながら、問題はこれだけではありませんでした。問題のコードは、アプリケーションでめったに使われていない部分に潜んでいたのです。
次に、障害発生中のAPM(アプリケーションパフォーマンス管理)トレースを分析して、障害に何らかのパターンがあるかどうかを探しました。そして、一般向けアプリケーションのレスポンスタイムが、外部Web呼び出しの待機によって著しく増加しているにもかかわらず、ミドルウェアのレスポンスタイム増加はそれよりもずっと小さいことが判明しました。
これと同じパターンがERPシステムでも見られるかどうかを顧客のチームに問い合わせましたが、その様子はありませんでした。何かがおかしいのですが、どこがおかしいのかはわかりませんでした。そこでミドルウェアに焦点を絞ることにしました。
ある障害が発生したときに、ミドルウェアのプロセスでスレッドを完全に使い切っていることに気づきました(アプリケーションサーバーでhtopを利用)。そこで、ミドルウェアと一般公開用アプリのコンカレンシー設定を比較してみると、大きな食い違いが見つかりました。
- 一般公開アプリ
- 2つのインスタンスのそれぞれについて、ワーカー数4、ワーカーあたりのスレッド数5
- ミドルウェア
- 2つのインスタンスのそれぞれについて、ワーカー数1、ワーカーあたりのスレッド数5
応急処置として、ミドルウェアのワーカー数を2に増やしました。また、NewRelicのリクエストキューイングをトラッキングするために、Haproxy設定にX-Request-Start HTTPヘッダーを追加しました。
この変更によって障害の頻度は大幅に下がりましたが、問題が完全に解決したわけではありませんでした。
私たちは、一般公開アプリからの負荷をミドルウェアが処理しきれなかったという仮説を立てました。これを証明する必要があります。
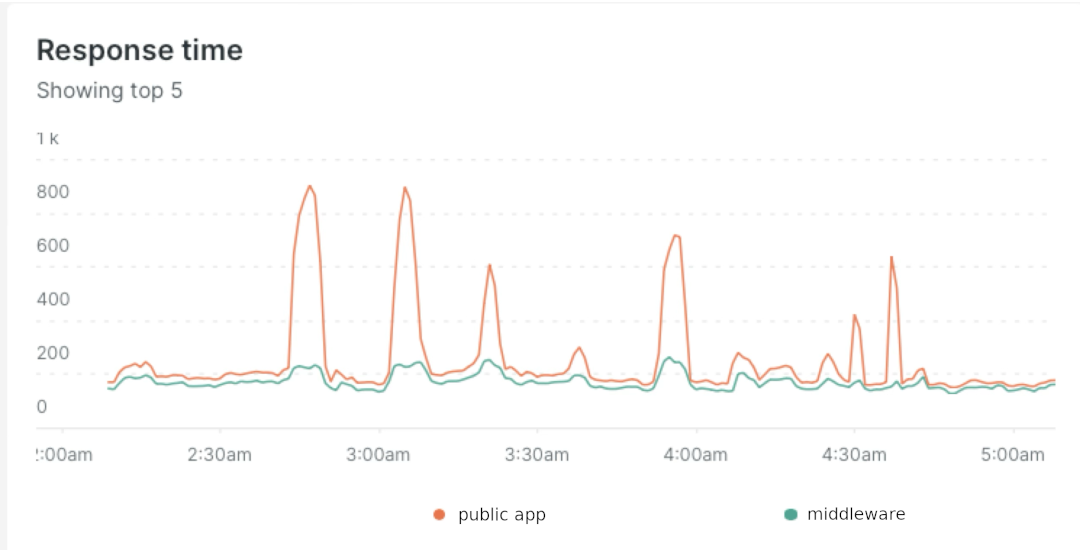
また、障害発生中にミドルウェアのリクエストキューイングをNewRelicでトラッキング開始しました。

顧客と合意した予算を使い切ったため、ここで調査はいったん中断されました。
🔗 調査 -- 第2ラウンド
数か月後、顧客から再び連絡がありました。当時の私たちは一般公開用アプリのRubyとRailsのアップグレードプロジェクトを開始しており、例の安定性の問題をさらに調査して欲しいという依頼を受けました。
今回は前よりも準備が整っていて、アップグレードプロジェクトでアプリケーションに関する知識や
、ミドルウェアとERPシステムの関係についての知識も以前より多く蓄積されていました。私たちは最初の調査のときから、ミドルウェアがボトルネックになっているという強い仮説を立てていました。そこで、ミドルウェアの完全なログ出力をNewRelicに追加してログの分析を開始しました。
そして、ミドルウェアのスループットが一般公開アプリに比べて桁違いに大きいことを突き止めました。そこから、ミドルウェアは一般公開アプリケーションだけで使われていたのではないことも判明しました。ミドルウェアが内部アプリケーションからのトラフィックも処理していたために、負荷が著しく増大していたのです。

私たちの理論を確かめるために、ミドルウェアの負荷を人為的に増やすことで一般公開アプリの障害を引き起こせるかどうかを試してました。
結果は予想通りで、ミドルウェアの負荷が大きくなると一般公開アプリで障害が発生したのです。これによって、ミドルウェアのコンカレンシー設定が最適ではなかったという私たちの仮説が強化されました。
🔗 Pumaコンカレンシーの最適な設定
RailsアプリケーションサーバーのデフォルトであるPumaは、マルチプロセス、マルチスレッドのモデルを利用しています。
RailsにおけるPumaのデフォルト設定では、ワーカーあたりのスレッド数として5という値が長年設定されていましたが、DHHがこの値を下げることを提案しました(#50450)。興味深い議論の後、Rails 7.2からワーカーあたりのスレッド数が3に引き下げられました。
なお、この値についてはRailsのパフォーマンスに関するエキスパートであり、PumaのコミッターでもあるNate Berkopecの経験則もあります。
最適な数値は、常に「1 CPUコアあたり1 Pumaワーカープロセス」です。そのうえで、最大負荷時にCPUコアが十分活用されるようにスレッド数を調整してください。
Nateのアドバイスに沿って、私たちはワーカー数を増やすのではなくスレッド数を調整することに決めました。それまでの私たちは、Rubyのスレッドの効率をネイティブスレッドより低下させる(悪名高い)GVLが存在していることで、スレッド数を増やすことをためらっていたのです。
このときから、私たちは既成概念に囚われずに考えるようになりました。Railsアプリケーションであるこのミドルウェアは、デフォルト設定を前提として設計された典型的なRailsアプリケーションと果たして似ているのか、違うとしたらどう違うのでしょうか?
このミドルウェアアプリケーションにおけるトランザクションの内訳を比較してみましょう。
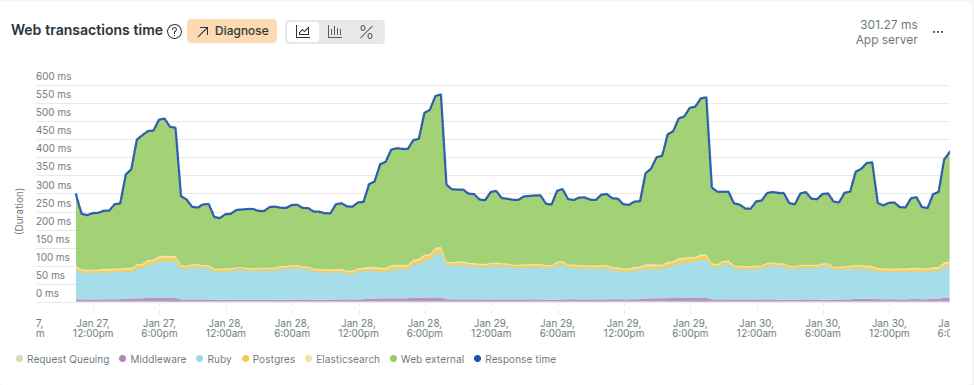
私たちが手がけた別のRailsアプリケーションでは以下のようになっています。

両者の違いがおわかりでしょうか?ミドルウェアアプリの内訳は、ほとんどが外部リクエストの処理で占められており、いわゆるI/O-boundであることを示しています。I/O-boundの負荷ではスレッド数が多いほど有利になります(スレッドはほとんどの時間をI/O待ちに費やすため)。RubyはI/O待機中にGVLを解放するので、このシナリオではスレッドの利用効率が高まります。
🔗 ソリューション: Pumaのコンカレンシー設定を調整する
安全かつインクリメンタルなデプロイを行うため、Ansibleのデプロイ用ロールを調整して、アプリケーションサーバーごとに異なるPuma設定をサポートするようにしました。また、サーバーごとに設定される合計スレッド数に基づく重み付けを導入するために、haproxy設定も調整する必要がありました。
これにより、さまざまな設定を段階的にテスト可能になりました。変更は一度に1つのサーバーに対してデプロイするようにし、システムを綿密に監視しました。
それと並行して、デプロイを短時間でロールバックするメカニズムの実装方法についても調査を進めました。従来のデプロイのロールバックは30分もかかり、しかも完全にデプロイし直す必要があったのです。そして、デプロイ用のカスタムアプリケーションを使わずにAnsibleベースでロールバックする方法を見つけました。これにより、ロールバック時間をわずか3分に短縮できました。
これまでPuma設定の変更をロールバックする必要に迫られたことは一度もありませんでしたが、そのための選択肢を持っておくのはよいことでした。これはアップグレードプロジェクトの方で非常に役に立ちましたが、それについてはまた別の機会にということで。
テストを繰り返して、最適なPuma設定を探り当てました。
- ミドルウェア: ワーカー数3、スレッド数3
- 一般公開アプリ: ワーカー数3、スレッド数9
最後に、一般公開アプリで障害テストを繰り返しました。
元のミドルウェア設定の場合は、負荷が増加すると一般公開アプリがクラッシュしました。
新しい設定の場合は、システムは安定し続けました。
どちらのテストについても、abベンチマークツールでまったく同じパラメータを指定して実行しました。
以下の結果をご覧ください。

🔗 データベースのコネクション数
変更を両方のサーバーにデプロイする前に、データベースのコネクション数についてもチェックしました。すると、新しい設定ではデータベースコネクション数の上限に非常に近づいていることが判明しました。
しかし待ってください。アプリケーションのその部分の振る舞いは何だか独特ではありませんか?上述したミドルウェアアプリの内訳グラフで、黄色い部分(データベース)がやけに狭いことに気づきましたか?
取り急ぎ調査してみたところ、ミドルウェアは認証と認可以外にデータベースを利用していないことが判明しました。そこで私たちは、認証と認可が完了したら直ちにコネクションをプールに戻しても安全であることを確認しました。
authorize! :perform, @task
ActiveRecord::Base.connection_pool.release_connection
# 以下の処理には長時間かかる
render json: @task.perform
これによって、ミドルウェアが利用するデータベースコネクション数を大幅に削減できました。20個のスレッドで構成されたアプリケーションプロセスが利用するデータベースコネクションは、わずか2個にまで減ったのです。
🔗 最後の考察
変更後、システムの安定性は大幅に向上し、顧客はこの結果に大いに満足してくれました。
しかし改善の余地はまだまだあります。リクエストごとに一般公開アプリがミドルウェアに依存しているのを解消できると効果があると思われます。これはおそらく、キャッシュと最終的な一貫性パターンで達成できるでしょう。
概要
元サイトの許諾を得て翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。